Learning Basketball Analytics - Week 1 - Scraping Basketball-Reference
November 28, 2021

Introduction
Welcome to week one! I’m still making my way through Basketball on Paper, but I wanted to make sure I got a blog out this week (consistency, remember?).
As I work through the book and try to build models or do analysis, I know I’ll need data. So, for this week, I’ll walk through how I built a basic webscraper using BeautifulSoup. The webscraper grabs advanced team stats off of Basketball-Reference and saves them to a CSV for future use.
Prerequisites
To build the scraper, I used the following tools:
- VSCode
- My go-to IDE for Python development
- BeautifulSoup
- The package used to perform the webscraping
- GIT
- The tool used for version control and pushing my artifacts to GitHub
- Python (v3.8.5)
- Downloaded via Anaconda
It might be worth finding a good guide on configuring your Python environment/tools. A good IDE alternative to VSCode is Spyder (also available via the base Anaconda installation).
And now.. the webscraping!
1. Import libraries and define parameters
#Import requests, csv, os, and BeautifulSoup
import requests
import csv
import os
from bs4 import BeautifulSoup
Library Purposes
- Requests
- Requests is used to grab and store the webpage content that BeautifulSoup will parse through
- CSV
- CSV will be used to write our advanced stats dataframe to a CSV file for future use
- OS
- I use OS to build the path for saving my CSV file, but there could be other ways to do this
- BeautifulSoup
- BeautifulSoup is the tool that I use to parse through the webpage content and find the data to store to a dataframe
#Create a list of years to pull data from
years = ['2022']
#Create an empty list to store the data
nba_adv_stats = []
#Create the header row with labels from the table
url = "https://www.basketball-reference.com/leagues/NBA_" + years[0] + ".html"
The first thing I did was visit Basketball-Reference and decide which table of stats I wanted to scrape. After some searching, I decided that the URL in the code snippet above contained a good number of tables that I thought I could use in analyses (had to google that plural). For this exercise, I’ll be trying to scrape the Advanced Stats table.
I created a list containing the years because I could then easily alter this scraper to loop through the list and pull stats for multiple years if needed.
Finally, the empty list above was initiated to store the advanced stat data that I wanted to grab.
2. Store the webpage content and define the table headers
#Get the webpage content from Basketball-Reference
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
Using the URL defined above, I used requests to grab and store the webpage content. BeautifulSoup provides us an object which stores the webpage data.
#Find the advanced stats header row (skip the top header row and ignore rank)
adv_stats_table = soup.find('table', attrs={'id':'advanced-team'})
adv_stats_header = adv_stats_table.find('thead')
headers = adv_stats_headers.find_all('th')
headers = [ele.text.strip() for ele in headers[6:]]
This part always feels a little bit like hunting and pecking to me, but I’ll try to outline my process. When I visit the URL, find the table that I want, and right-click to inspect, I see the following HTML:
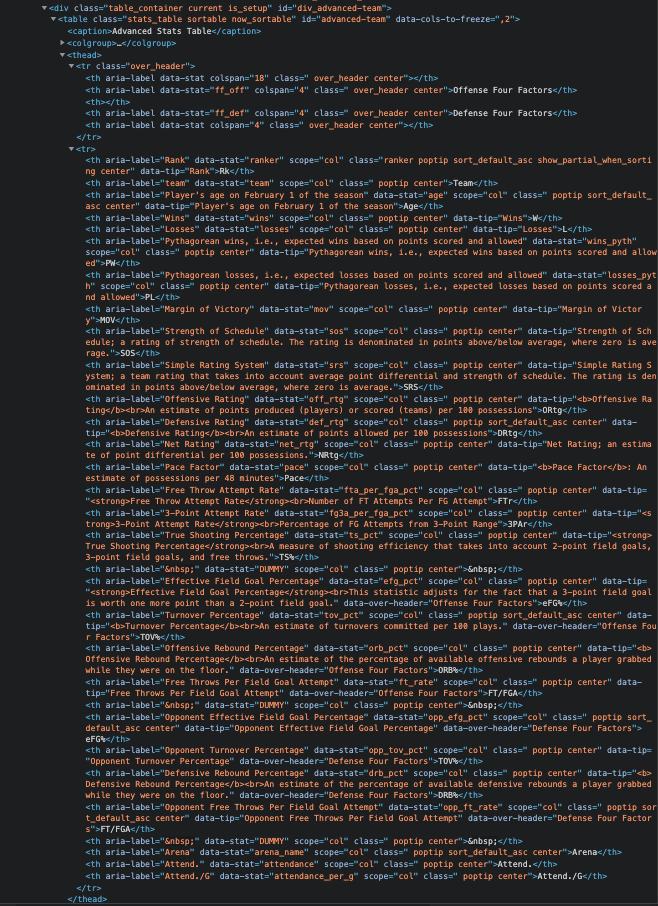
I see that the table has an id element named advanced_team. I’ll pass that name to the soup object to find and I’ll save that to my adv_stats_table object. From there, I do essentially the same thing to find the other elements. I find the header row by looking for the thead element. Then, I find all of the individual headers by looking for all of the th elements.
I do notice that there is a first row that has the headers of Offense Four Factors and Defense Four Factors, but I want to skip those. To do that, I start only pulling in the headers that appear after.
#Manually add the 'Year' header
year_header = ['Year']
combined_headers = year_header + headers
#Append the headers to the beginning of the nba_adv_stats list
nba_adv_stats.append([ele for ele in combined_headers])
Since I plan on potentially using this scraper to pull data for multiple years, I include a Year header which I’ll eventually populate with 2022 since that is the year in the URL on Basketball-Reference. Once I have all of the headers, I append it to my nba_adv_stats list.
3. Find the table body and scrape the data
#Find the advanced stats body
adv_stats_body = adv_stats_table.find('tbody')
adv_stats_rows = adv_stats_body.find_all('tr')
Using the same process as above, find the tbody element. Inside of the tbody element, find all of the rows that are marked with the tr element. The data we want is located within each of those rows.
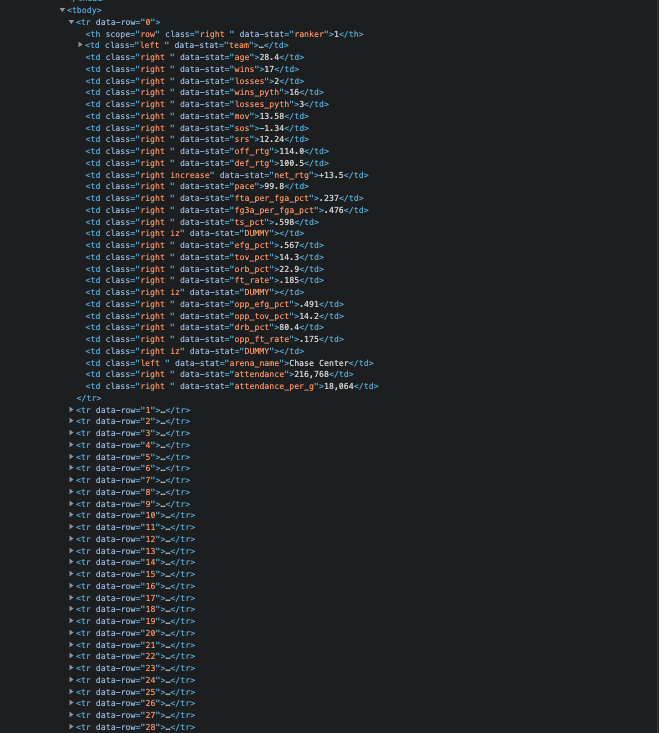
#for each year in the years list, add the advanced stats data
for year in years:
#For each row in the advanced stats table, add the team data to the nba_adv_stats list
for row in adv_stats_rows:
#Populate the Year column (will need to update once this is a loop)
year_column = [year]
#Find the rest of the data columns
data_columns = row.find_all('td')
data_columns = [ele.text.strip() for ele in data_columns]
#Combine columns
combined_columns = year_column + data_columns
#Combine the columns and add them to the nba_adv_stats list
nba_adv_stats.append([ele for ele in combined_columns])
I loop through all of the years (pretend there isn’t more than one) and I loop through all of the rows. This will allow me to get data for every year that I need and for every team that is listed in the advanced stats table for that year.
Inside of the rows, the data is stored in the td element. We will find all of those data elements and store them in our data_columns object. Once we have all of the data that we need (or that is available :) ), we will combine it with our year column that we created. After we’ve combined all of our data, we will add it to our nba_adv_stats list. It is time to write it to storage!
4. Save the file to a CSV for future use
#Create a dynamic CSV file name based on the year scraped
csv_path = os.path.join(os.getcwd(), "data/")
csv_file = csv_path + "nba_adv_stats_" + years[0] + ".csv"
#Write the nba_adv_stats list to a CSV
with open(csv_file, "w", encoding="utf-8", newline='') as csvfile:
writer = csv.writer(csvfile)
for data in nba_adv_stats:
writer.writerow(data)
This will depend on your use case(s), but I chose to name my file based on the year of data that I’m grabbing. If I update my scraper to pull for multiple years, I could either have different CSV files based on the year or I could create one combined CSV file.
I wanted to save the data to a specific data/ folder that is located in the parent directory (my webscraper is stored in a scraper folder).
Once the CSV file is created, I’m ready to do some exploratory analysis on the data!
Artifacts
If you are interested in the final webscraper or data, please find the links below:
- Basketball-Reference Webscraper
- 2021-2022 Team Advanced Stats
- Note: This is as of 11/28/21.
As always, feel free to follow me at @aaronpetryio for updates and other ramblings.